While replication was sufficient for datasets which can fit on each instance of your machines, we’ll need partitioning to break our data into partitions
- Note: there are lots of synonyms for partition- shard (MongoDB/Elasticsearch/SolrCloud), region (HBase), tablet (Bigtable), vnode (Cassandra/Riak)
Why do we want to do this? Mostly for scalability
- You can distribute a large dataset across many disks by putting different partitions on different nodes in a shared-nothing cluster
- If you need to query a single partition, that node can independently execute the query
Partitioning and Replication
It’s important to note that partitioning is almost never employed alone- and often is combined with replication.
What does this mean?
- Records will be stored on several nodes for fault tolerance
- Additionally, nodes can store several partitions
This leads to interesting architectures- for example, in a leader-follower replication model, you will often have partition leaders and followers (for separate partitions) on the same node!
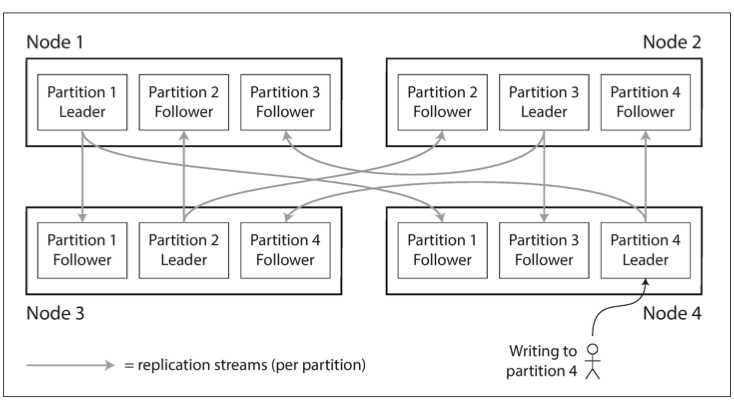
Partitioning Key-Value Data
How does one decide how to partition data?
Remember, our goal is to spread the query load and data evenly across the nodes
The naive approach would be to randomly assign records to nodes. The data would certainly be eveny distributed, but can you think of any issues with this approach?
- You wouldn’t know which node the item is on! You’d have to query all the nodes!
Let’s explore some better methods.
Partitioning by Key Range
Method of partitioning: partition based on separate continuous ranges of keys (vis. a library)
How to choose the boundaries? Either
- Administrator
- Or automatically (see TODO)
Cons
- Can lead to hotspots- doesn’t necessarily delineate partitions based on query volume
Pros
- Can keep sorted order within each partition- great for range queries
Partitioning by Hash of Key
Method of partitioning: partition based on separate continuous range of hashes of keys
How to choose a hash function?
- Goal of hash function: take skewed data and uniformly distribute it
- Doesn’t need to be cryptographically strong
- Real-world hash functions: MD5 (Cassandra, MongoDB), Fowler-Noll-Vo (Voldemort)
Pros
- Good at distributing keys fairly among partitions
Cons
- Terrible for range queries
Note: Consistent hashing is what we call hash partitioning when you pseudorandomly pick the partition boundaries. It is rarely used and doesn’t actually work well.
Relieving Hot Spots
So, hashing a key can help reduce hotspots, but doesn’t guarantee a solution.
What should you do if you end up with a highly skewed workload? (e.g. a celebrity joins your burgeoning social media platform)
Sadly, modern databases typically can’t account for massive skewing, so you’ll have to handle it in your application
Partitioning and Secondary Indexes
Remember: secondary indexes
But how do we partition data when we have secondary indexes?, which don’t usually identify records uniquely.
2 main approaches to partitioning a database with secondary indexes
- Document-based
- Term-based
Partitioning Secondary Indexes by Document
Example scenario:
- Website for selling used cars
- You’ve partitioned database by unique Document ID
- You want to let users filter by color and make, so you need a secondary index on color nad make
The document-based approach
- Separate (local index) secondary index for each partition
- Secondary index maps field (ie. color) to the unique Document ID
Con
- You’ll have to query all partitions if you want to search for specific color or make (unless you’ve done something special in the set up)
Note: this approach to querying partitioned database is sometimes referred to as scatter/gather
Partitioning Secondary Indexes by Term
The term-based approach
- A global index which covers data in all partitions
- This index must be partitioned
- Can use hash or term itself
Pros
- More efficient reads (no need for scatter/gather)
Cons
- Writes are slower
Rebalancing Partitions
As well know, nothing good in life lasts. The same is true in databases. Here are some changes you’ll need to account for
- Query throughput increases → you’ll want to add more CPUs
- Dataset size increase → you’ll want to add more disks and RAM
- Machine fails → other machine needs to take over
But how can you do this when you have your distributed nodes? Through a process called rebalancing.
What are the goals for rebalancing?
- (i) Keep load fairly shared
- (ii) No downtime
- (iii) As little data change
Strategies for Rebalancing
Hash mod N (don’t do it this way!)
The approach: Assign records to partitions based on their hash mod N
Why is this terrible?
- As N (number of nodes) changes, you’ll need to switch a whole bunch of data!
Fixed number of partitions
The approach:
- Create a fixed number of many partitions
- Assign several to each node
- Upon new node’s creation, have the new node steal some partitions until they’re distributed evenly
Real-world use: Riak, Elasticsearch, Couchbase, Voldemort
Dynamic partitioning
The approach: Divide partition into two when it exceeds a configured size. Converse as well- when partition shrinks to specific level, merge with adjacent partition
Pro: number of partitions adapts to data volume
Caveat: empty database must start with a single partition (how would you know where to draw partition boundaries?), so initially all writes are handled by a single node
Partitioning proportionally to nodes
The approach: have a fixed number of partitioner per node- thus, the size of each partition grows proprtionally to dataset size.
Operations: is Rebalancing Automatic?
Does rebalancing happen automatically or manually?
Generally, it is good to have a human in the loop for rebalancing
- Fully automating rebalancing can be efficient, but unpredictable
- Rebalancing is expensive: important to be careful
Request Routing
We have now: parittionined our dataset across nodes across machines
But, how does client know which node to connect to? The nodes which partitions are assigned to is constantly changing
There are a few approaches we can take
- Let client contact any node (node intermediary)
- If node owns partition, it handles the request
- Else, passes along request to appropriate node and passes back reply
- Send requests to routing tier first (load balancer)
- Routing tier determines node which should handle each request + forwards it to the node
- Make client aware of partitioning
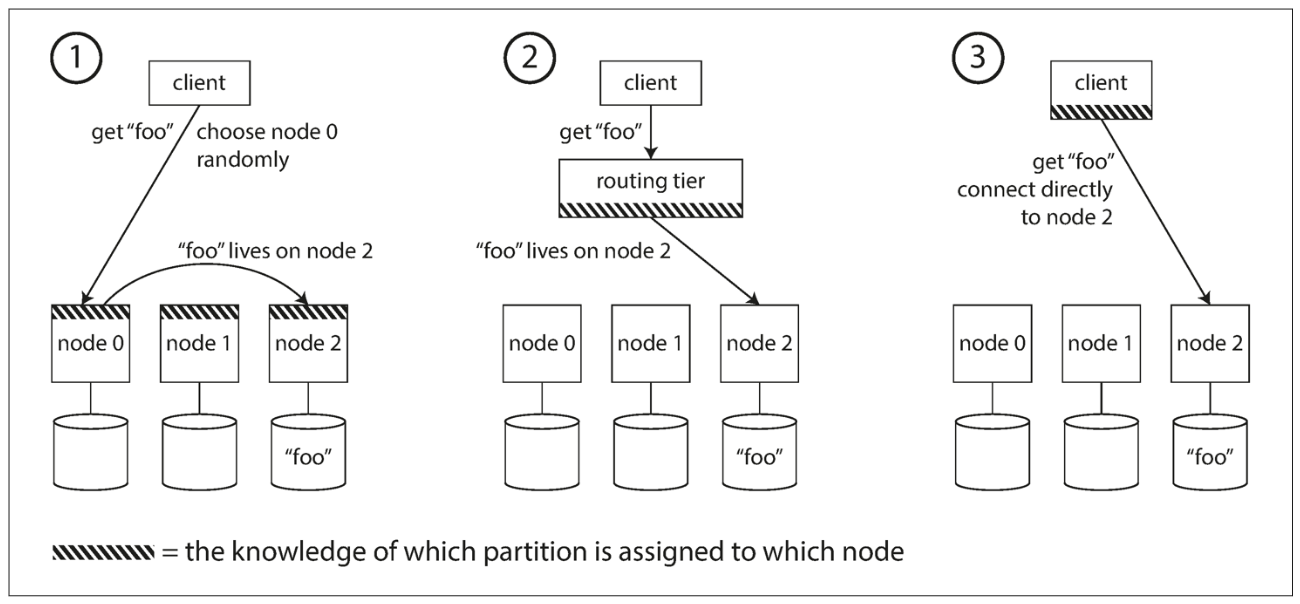
But still: how do the components that make the routing decision actually learn about the changing assignmnets of partitions to nodes?
- Separate coordination system (e.g. Zookeeper)
- Nodes register in ZooKeeper and ZooKeeper maintains mapping
- Routing tiers subscribe to info in ZooTier
- Gossip protocol
In sum
Partitioning
- Goal: spread data + query load evenly across machines, avoiding hot stpots
- Necessary when: storing + proceessing data on single machine isn’t feasible
2 main approaches
- Key Range Partitioning
- Hash Partitioning
Partitioning and secondary index. Partitioning secondary indexes-
- Document-partitioned indexes
- Term-partitioned indexes
Query routing